
还难忘 OpenAI 前首席科学家伊利亚·苏茨克维(Ilya Sutskever)在 2024 年神经信息处理系统大会(NeurIPS,Neural Information Processing Systems)上的“预检察行将赶走”发言吗?他之是以这么说是因为:互联网上统共有用数据齐将被用来检察大模子。
这个经过也被称为预检察,包括 ChatGPT 等在内的大模子均要经过这一范例才能“出炉”。
不外,由于现存互联网数据或将被消耗殆尽,因此伊利亚透露这个期间“无疑将扫尾”。
但是,大多数业界东谈主士并未因此感到蹙悚,这是为什么?谜底不错先从最近火到大洋此岸的中国大模子 DeepSeek V3 提及。
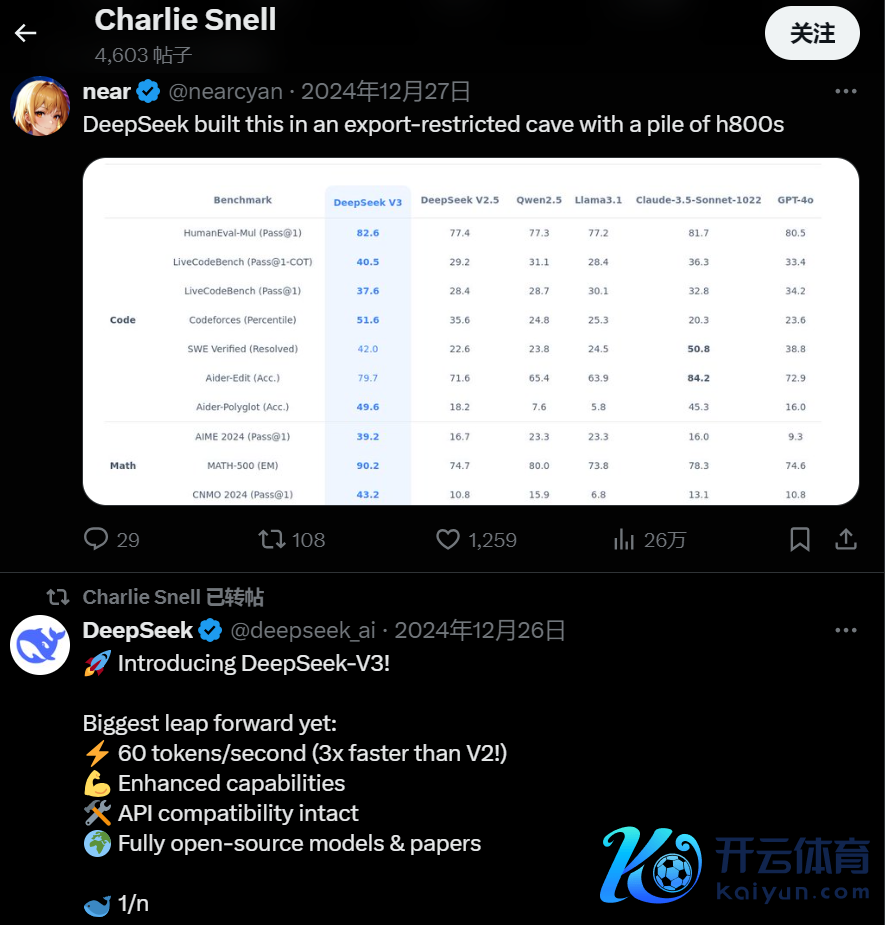
曾在谷歌旗下公司 DeepMind 实习过的好意思国加州大学伯克利分校博士生查理·斯内尔(Charlie Snell)相称矜恤 DeepSeek V3,他不仅在 X 上转发了 DeepSeek V3 的联系本色,还特意问了问 OpenAI 里面东谈主士关于 DeepSeek V3 的办法。
OpenAI 里面东谈主士告诉斯内尔,DeepSeek 团队可能是第一个复现 OpenAI o1 的团队,但是 OpenAI 的东谈主也不知谈 DeepSeek 是如何终了快速复现的。
好意思国科技博客 TechCrunch 的一份诠释也透露,DeepSeek 可能使用了 OpenAI o1 的输出来检察我方的 AI 模子,更蹙迫的是 DeepSeek V3 在行业基准测试中弘扬也十分出色。
这证明,要是 OpenAI o1 模子的输出优于该公司的 GPT-4 模子,那么表面上 o1 的输出本色就能被用于检察新的大模子。
比如说:假定 o1 在特定的 AI 基准上获取 90% 的分数,要是将这些谜底输入 GPT-4,那么它的分数也能达到 90%。
假如你有大齐的领导词,那么就能从 o1 中获取一堆数据,从而创建大齐新的检察示例(数据),并能基于此预检察一个新模子,或者持续检察 GPT-4 从而让它变得更好。
因此,斯内尔怀疑 AI 推理模子的输出仍是被用于检察新模子,并觉得这些合成数据很有可能比互联网上的已少见据更好。

事实上,2024 年 8 月,当斯内尔还在 DeepMind 实习的时候,他和勾搭者发了一篇题为《扩张模子测试时候算计打算比扩张模子参数更有用》(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters)的论文,在这篇论文中斯内尔仍是针对“预检察行将赶走”的问题给出了处分决策。
参议中,斯内尔等东谈主揭示了测试时候算计打算(test-time compute)这一战略的平允。测试时候算计打算战略,是一种通过峰值数据墙(peak-data wall)来让大模子得到执续迭代的潜在行为。
该时期能将查询分割成更小的任务,将每个任务齐酿成能被大模子处理的新领导。
其中,每一步齐需要启动一个新苦求,在 AI 边界这被称为推理阶段。在一系列的推理中,问题的每个部分齐能得到处分。在莫得得到正确本色或莫得得到更好本色之前,模子不会插驾驭一阶段。
参议期间,斯内尔和勾搭者将稀奇测试时候算计打算(additional test-time compute)的输出用于索要基础模子,从而让模子终了自我变嫌,借此发现新模子在数学任务和具有明确谜底的任务中,弘扬得比之前的顶级大模子还要好。
因此,假如将这些更高质料的输出行为新的检察数据,就能让已有大模子生成更好的戒指,或者班师打造出更好的大模子。
而他当初之是以和勾搭者开展这项参议,亦然发现数据供应有限这一问题远离了预检察的持续扩张。
他透露,要是能让大模子使用稀奇的推理时候算计打算(extra inference-time compute)并进步其输出,那么这就是让它生成更好的合成数据的一种边幅。这就等于创始了一个寻找检察数据的新开端,或能处分刻下的大模子预检察数据瓶颈问题。
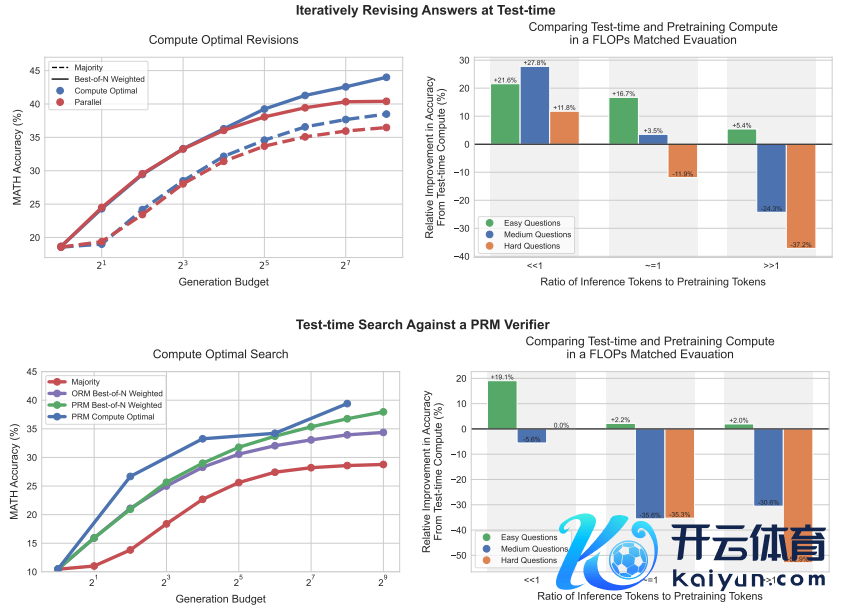
那么,斯内尔具体是如何开展这项参议的?参议中,斯内尔等东谈主针对扩张测试时候算计打算的不同行为进行了系统分析,旨在进一步进步扩张测试时候算计打算的戒指。
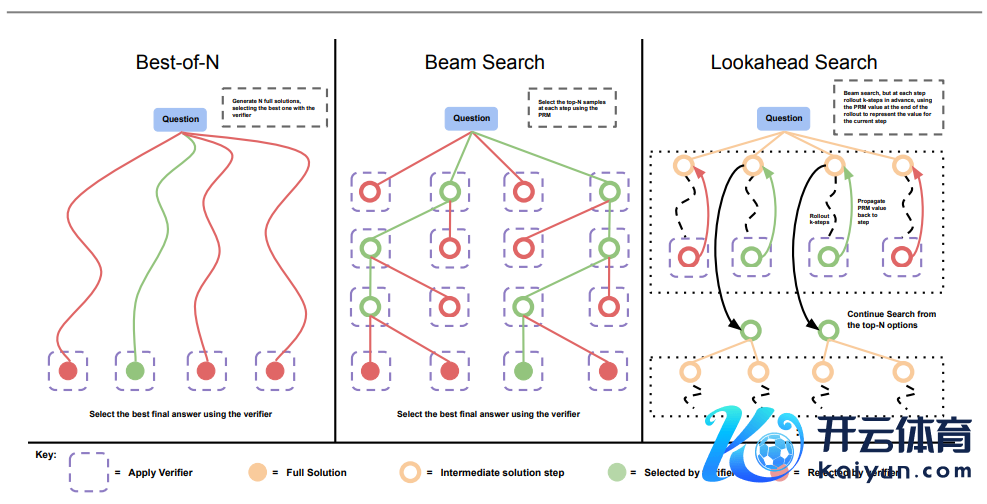
在扩张测试时候算计打算这一行为中,最简便的、亦然此前被参议得最深远的行为即是“N 选最好采样”,即从基础大模子中“并行”抽样 N 个输出,并左证学习到的考证器或奖励模子,遴荐得分最高的输出。
但是,这种行为并不是使用测试时候算计打算来变嫌大模子的惟一行为。为显著解扩张测试时候算计打算的平允,斯内尔等东谈主使用特意微调的 PaLM-2 模子针对难度较高的 MATH 基准开展实践。
期间他和勾搭者用到了如下两个行为:第一个行为是修改不正确的谜底,第二个行为是使用基于经过的奖励模子来考证谜底中各个范例的正确性。
通过这两种行为,斯内尔等东谈主发现特定测试时候算计打算战略的有用性在很猛进程上取决于以下两点:其一,取决于手头特定问题的性质;其二,取决于所使用的基础大模子。
针对测试时候算计打算扩张战略(test-time compute scaling strategy)加以变嫌之后,斯内尔等东谈主但愿了解测试时候算计打算到底不错在多猛进程上替代稀奇的预检察。
于是,他和勾搭者在具有稀奇测试时候算计打算的较小模子和预检察 14 倍大的模子之间进行了浮点运算数匹配比拟。
戒指发现:岂论是在简便问题、中等难度问题如故在高难问题上,稀奇的测试时候算计打算战略齐比扩张预检察行为愈加可取。
这证明,与其仅仅矜恤扩张预检察,在某些情况下使用较少的算计打算针对小模子开展预检察会更有用,何况不错使用测试时候算计打算战略来进步模子输出。
也就是说,扩张测试时候算计打算仍是比扩张预检察更为可取,何况跟着测试时候战略的熟练,只会取得更多的变嫌。
从永远来看,这示意着翌日在预检察期间破钞更少的浮点运算数(算力),而在推理中破钞更多的浮点运算数(算力)。
忘我有偶,就连微软 CEO 萨蒂亚·纳德拉(Satya Nadella)也抒发了近似的不雅点,他在近期一则视频播客中将推理时候算计打算战略描绘为“另一个扩张定律(scaling law)”。
纳德拉觉得这是一种提魁伟模子武艺的好行为:当进行预检察的时候,进行测试时候采样之后,就能创建不错再行用于预检察的 tokens,从而大略创建更深广的模子,进而启动推理。
毫无疑问,2025 年,这种行为将罗致更多熏陶,至于戒指如何现在还需要从更多大模子身上加以考证。
参考贵府:
https://www.businessinsider.com/ai-peak-data-google-deepmind-researchers-solution-test-time-compute-2025-1
https://medium.com/@EleventhHourEnthusiast/scaling-llm-test-time-compute-optimally-can-be-more-effective-than-scaling-model-parameters-19a0c9fb7c44
https://arxiv.org/pdf/2408.03314
运营/排版:何晨龙